藏品博覽
走進語言譜系樹
編者按🐔:
耀世娱乐世界語言博物館自2019年12月開館以來🏨,一直秉持“語匯世界,言聚全球”(Words, Worlds)的立館理念😊,致力於彰顯世界語言多樣性♦️,匯聚全球知識𓀇。為全面開展人文交流、科普教育和學術研究,本欄目推出“藏品博覽”專題,陸續推送以世界語言多樣性為主題的科普介紹,展陳世界語言多元面貌,講述世界語言文字故事🤏🏻。
 展品坐標👰🏼♀️:上外世界語言博物館“說🕉,溝通世界”展廳
展品坐標👰🏼♀️:上外世界語言博物館“說🕉,溝通世界”展廳
01
引入
“英語是一門屬於印歐語系日耳曼語族西日耳曼語支🧺、起源於英國英格蘭地區的語言”(維基百科)👨🏽💼😵。對於任何一門語言,我們都會聽到類似的描述。我們會談起這門語言的地理分布和使用人口。我們也會說到這門語言的構成元素🍯,即音系詞匯語法的特征🐣。我們也經常會提及這門語言的譜系從屬🧑🏻🦲。的確,了解一門語言的譜系從屬,可以告訴我們該語言與其他語言之間的歷史關系、演化路徑以及該語言和地理與人口遷徙之間的關系💛。
世界上目前存在著7000多種林林總總的人類自然語言(Ethnologue)。這些語言相互之間顯然並不是毫無關聯的。我們目前就在用譜系從屬的思路嘗試厘清其中不同語言間的親緣關系。這種用家庭族譜來類比語言之間親緣關系的思路,就是譜系樹模型的基本思路。
譜系樹模型(tree model, 德語💭:Stammbaum Theorie)自1853年被德國語言學家施萊歇爾推廣以來,已經成為了歷史語言學研究中最重要的理論模型之一,也成為了我們直到今天認識語言之間的親屬關系的主流模型。
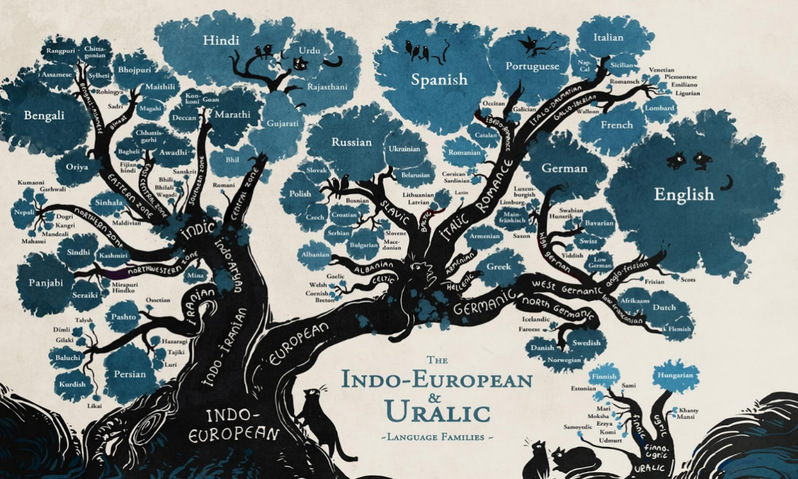
圖1. 歐洲的語言譜系分布
這樣一個模型並不是語言學家一拍腦門就想出來的🚹。此外,雖然該模型從未被徹底否定,譜系樹模型的有效性一直以來在語言學界內部也存在爭議。本文將會簡要地對譜系樹模型的前世今生進行介紹🧝🏿♀️。希望通過本文的說明🧑🏽🎓,你也會對我們認識人類語言間關系的這一個重要的語言學模型有更深的理解🍞⏩。
02
譜系樹的起源和發展
1.從“巴別塔”說起
相信每一個上外的學生都聽說過源於《聖經·創世記》的巴別塔的故事🐦🔥。在大洪水之後🍳➝,人類的後代集結在一起,準備建造一座巨大的高塔直通天空🤟🏿,以使他們能夠在塔頂上建造一座高到能接近上帝的城市。然而,上帝認為這是傲慢的人類在妄圖挑戰他的權威🛣,便讓人類的語言變得混亂✊🏻,以至於彼此之間無法理解與溝通✊。因此✯,人類被迫放棄建造巴別塔,並分散到世界各地𓀓,成為了不同的民族,說起了無法互相交流的語言。

圖2. 勃魯蓋爾畫中的巴別塔
巴別塔的故事是《聖經·舊約》中對人類語言多樣性的宗教解釋🥽。在現代看來⚰️🚙,這一故事似乎有些荒誕🔛,但不知道細心的你有沒有發現隱藏在“巴別塔”中的重要前提。沒錯,巴別塔的故事體現了語言分化的概念。巴別塔的故事認為人類的不同語言是從一門祖先語言中分化而來的。而這也正是下文將會提到的譜系樹模型的重要原理之一。對於剛剛經過中世紀、深受基督教思想洗禮的歐洲🪻,巴別塔的故事也為其後歐洲學者對於語言的研究打上了“存在一種最初的語言✍🏻,其他語言都是從這種語言演變而來”這樣的思想的烙印🖐🏻。
希波的奧古斯丁(Augustine of Hippo,或稱聖奧古斯丁🍱,公元354—公元430)是有記錄的最早對家族譜系和語言譜系做出類比的神學家。他的神學成為後來基督教教義的基礎,對西方教會的影響頗深。他在對舊約的研究中假設,諾亞(Noah)後代的每一個人都建立了一個國家,而每一個國家都被賦予了自己的語言😛:亞述人的語言屬於亞述(Assur),希伯來語屬於希伯(Heber),以此類推。他一共確定了72個國家、72位創始人和72門語言👩👦👦。巴別塔的混亂和分散的故事發生在希伯的兒子、閃(Shem)和諾亞的後裔佩勒格(Peleg)的時代。同時,奧古斯丁提出了一個與其後的語言研究者十分類似的假設,即希伯家族“保留了這種被認為是人類共同語言的語言……因此被稱為希伯來語”🧏♀️。希伯來語成為了最初的語言——上帝將人類語言混亂之前的語言𓀄,亞當和夏娃在伊甸園的語言,而世界上的其他語言都是從希伯來語中🧑🏻🏫,與家族譜系的分化同時分化而來的🫶🏼。
2.航海大發現與印歐歷史比較語言學的興起
過了1000多年的時間,奧古斯丁的假設一直未曾受到大的質疑和挑戰。在此期間,由於宗教教義已經表明所有語言具有單一的起源——“希伯來範式”,而語言分化被描述為一個突然的腐化過程,歷史語言的研究者們大多將他們的研究局限於推測性的詞源學研究,試圖表明所有語言都至少繼承了一些希伯來語的詞匯。
新航路的開辟和航海大發現給這一範式敲響了喪鐘。隨著歐洲人對遠東以及新世界語言接觸與了解的深入🌓,新語言的數量已經遠遠超出了奧古斯丁所計算的72種。引美洲土著語言為例,英國博學家托馬斯·布朗(Thomas Browne🤹🏻♀️,1605—1682)提出“最初的語言混亂只影響到了在巴別塔工程中出現在示拿爾(聖經中巴別塔的建造地點)的人們……”🔒,而“在山腳下,在方舟停泊的地方……他們的原始語言可能隨著時間的推移分支到歐洲和亞洲的幾個部分……”的假設📣。在布朗看來,比希伯來語更早的原始語言的簡化可以解釋語言之間的差異,例如古代的漢語;而其他語言是通過“混亂♠︎、混合和腐化”從它演變而來的。由此🧘🏿,希伯來語作為最原始語言的假設也就不成立了🙂↕️。
布朗依舊沒有跳出宗教的框架,但他開始了對巴別塔故事中的災變論(catastrophism)史觀的質疑,首次設想出了語言逐漸演變的進化論(gradualism或evolutionism)的可能🧚♂️,並且提出了譜系樹分支結構的萌芽。語言研究者們從此將巴別塔的故事擱置在一旁📟,踏上了一條語言尋根之路。歐洲所有語言學家開始尋找所謂的“伊甸園之語(lingua prima,最初的語言)”。這種神秘的語言被賦予了“純凈”和“無汙染”的光環,而這些特質則是尋找目標語言的標準。
隨著“巴別塔”的轟然倒塌🧔🏻♂️,遠行世界各地的傳教士們為了方便傳教💇🏽♂️,開始調查、記錄和學習當地的語言。歐洲殖民者在得到了眾多語言數據的同時也開始了對語言標本的搜集和比較詞匯詞典的編寫。從大量的語言數據中尋找相似之處以找到古老純凈的原始語言的任務終究不是一無所獲的🧏🏿,因為梵語引起了歐洲的語言研究者們的註意🦅👍🏼。
早在16世紀,英國傳教士托馬斯·史蒂芬斯(Thomas Stephens)以及意大利商人菲利波·薩塞蒂(Filippo Sassetti)就已經註意到了梵語和拉丁語的相似之處。但直到英國語文學家威廉·瓊斯(William Jones,1746—1794)於1784年創立亞洲學會(the Asiatic Society)👳🏽♂️🧞,並在1786年的學會三周年演講中提出梵語、希臘語和拉丁語可能有著共同的根源👏🏼,並且它們可能還與哥特語、凱爾特語以及波斯語相關聯♉️,才將譜系樹模型的邏輯和語言比較研究相結合。瓊斯並不是第一個提出這些語言有共同祖先的學者🫶,他對語言的親屬關系判斷也有不少失誤(如他將古埃及語⇾、日語和漢語也納入了印歐語言的框架),且仍未擺脫《聖經》的框架,但由於其影響深遠,他在亞洲學會的貢獻一度被認為是歷史比較語言學的開端。
3.19世紀的歷史比較語言學
進入19世紀🧑🔧,人類科學技術迅速發展,現代的語言學也逐漸初步成型🧚🏻♀️🤌🏽,在當時主要體現為語文學家們對語言開展的歷史比較研究。其中,德國哲學家和語文學家弗裏德裏希·施萊格爾(Friedrich Schlegel,1772—1829)在《論印度人的語言與智慧》(1808)中首先提出了比較語法的概念🙇🏿。他反對梵語和歐洲語言間相似是由於借用或仿造的觀點,而是以梵語為祖先語,認為歐洲人源自印度。施萊格爾還認為,以多門語言內部內在結構💅🏼🤸🏿♂️、形態和語法規則上的比較🚶,可以給語言學家帶來關於語言譜系的嶄新知識,而他的比較語法也成為了歷史比較法的基礎💁🏿♀️。
雖然瓊斯沒有給他假設的“共同源語言”命名,也沒有進一步發展這個想法🗡,但當時的語言學家們普遍接受了這一理論⚜️。英國博物學家托馬斯·楊(Thomas Young)在對約翰·克裏斯托弗·阿德隆(Johann Christoph Adelung)和約翰·塞弗林·瓦特(Johann Severin Vater)所著《米特裏達梯👌🏼,或普通語言學》的評論(1813—1814)中,首次提出了眾多印歐學者所假設的作為印歐諸語原始語的“印歐語(Indo-European)”這一概念。而這也是該詞的在語言學意義上首次使用👮🏼♂️。楊的“印歐語”這一名稱,僅是當時諸多提議和構擬嘗試中的一個(如在德語世界還存在Indo-Germanisch,印度-日耳曼語)。這正式標誌著尋找印歐諸語的祖先語成為了歷史比較語言學的主要問題👨🏿💻,而隨著語言學家對找到聖經中原初語言的希望逐漸破滅,他們轉而重視共同印歐語的概念🔁,認為它是由在歐亞大陸平原上的遊牧部落所使用。不過,盡管他們充分論證了通過比較語言學的方法可以推斷出這種語言♕,但這一結論的得出確實和先前語言研究者們對“伊甸園之語”的不懈追求緊密相關⇢。
其後,奧古斯特·施萊歇爾(August Schleicher,1821-1868)推廣了歷史比較語言學的譜系樹模型(施萊歇爾稱之為Stammbaum)✤,在其中他有意用枝的長度表示語言分化之後經過的時間,並首次將構擬付諸實踐✒️🚝,用構擬的原始印歐語寫作了一個叫做《山羊和馬》的寓言故事🏋️♀️🕓。施萊歇爾將語言譜系樹和達爾文《物種起源》中的生物演化樹相類比,但這兩個模型分別是歷史比較語言學和演化生物學兩個學科獨立發展出來的👨🏻🍳,而這或許也體現了人類語言和物種在演化上的相似性🥩。至此🙏🏿,譜系樹模型得到了廣泛的推廣,成為了歷史比較語言學中最重要的模型。

圖3. 施萊歇爾的印歐語系譜系樹
(註🚶🏻♀️➡️:圖中的⟨ſ⟩現寫作⟨s⟩。“indogermaniſche urſprache”即為“原始印歐語”的德語說法🤸🏿♀️。)
施萊歇爾將原始印歐語首先分成兩支,“ſlawodeutſch(斯拉夫-日耳曼)”和“ariograecoitalokeltiſch(雅利安-希臘-意大利亞-凱爾特)”;從斯拉夫日耳曼支中又分出日耳曼支——德語的祖先語,以及“ſlawolitauiſch(斯拉夫立陶宛)”——諸斯拉夫語以及立陶宛語的祖先語🖊;而從雅利安-希臘-意大利亞-凱爾特支中“ariſch(雅利安語)”首先分化出去並成為了印度-伊朗語族的祖先語😶,之後希臘語和阿爾巴尼亞語分離,最後凱爾特語族和意大利亞語族分家。施萊歇爾正確地認識到了很多印歐語系內部語族之間的親屬遠近關系,如意大利亞語族和凱爾特比較接近◽️,但他在命名、結構和分支上也犯了很多錯誤,他的譜系樹和今天的印歐語系譜系樹還是有很大的差別的🍷。
03
譜系樹模型的基本原理
共同祖先和分支演化
譜系樹模型假設後代語言都源自一個共同的祖先語言,並且通過分支演化形成了多種語言。在這個模型中🍏➔,共同祖先語言被稱為原始語言(proto-languages),而各個後代語言則通過演化和分化產生💐🤰🏿。如果假設祖先語言不唯一🕵🏼,將導致無法建立清晰的分支關系,因為多個祖先意味著存在交叉和混合的演化路徑,使得語言之間的關系變得復雜而模糊🫡🧎♀️➡️,不再有明確的起源和發展路線可循,譜系樹也就將難以畫出🍍。
譜系樹的層級結構
和生物分類學將生物進化樹上的單位分為“界門綱目科屬種”類似,譜系樹模型上的語言也一般可以分為“語系”“語族”“語支”“語言(語種)”等層級。但譜系樹的層級並不像生物分類那麽具有明確定義的決定因素👨🦱。譜系樹模型上的每個層級在一定程度上顯示了語言之間的演化和發展關系👩🏻🦱。另外值得一提的是🏌🏼,在英語中譜系樹層級的概念並不是十分嚴格,語系、語族等都可以籠統地稱為“languages”🧑🦰🙌🏼,而語系一般稱為“language family”,語族可以稱為“branches(分支)”,語支可以稱為“sub-branches(亞分支)”,這或許是因為印歐語系的分類整體比較清晰所導致的。漢語中對譜系樹層級的稱呼從語系語族語支從大到小的順序是比較明確的,但也經常能看到有人錯誤地使用“語系”一詞,濫用“語系”指代“語族”甚至更小的語言分類層級的情況,如“拉丁語系(指羅曼語族或印歐語系)”“日耳曼語系、斯拉夫語系(均應為語族)”以及“北方語系(實應為官話方言)”,這些都是不規範的稱呼♤。
語言的分類最初並不是為了符合譜系樹模型。語系💸、語族等概念最初只是將在詞匯、語法等方面有很多相似性的語言進行歸類的標簽。美國語言學家約瑟夫·格林伯格(Joseph Greenberg,1915—2001)的推廣使這些層級納入了譜系樹模型的框架🚶♂️,而他這樣做很可能是受到了生物學的啟發。英國生物學家查爾斯·達爾文(Charles Darwin)提出進化論並在生物學中得到普遍接受。而此時生物分類學已經被卡爾·林奈(Carl Linnaeus)發明出來💁🏽🏌🏼。林奈使用二名法為每一個已知的生物種指定了一個種名和一個屬名。這些生物被按照生物層級結構排列在幾個門下🧖♂️,最終分支到各種不同的物種,而這種生物分類的依據是觀察到的物種之間共享的生理特征🤦🏿。是達爾文將共時的生物分類學框架套用到了他設想的“生命進化樹”上。此後🦹🏽♂️,這種新方法被不斷優化、改善,成為了系統發育學💆🏻♂️。這吸引了格林伯格。他提出要改變譜系樹模型,向譜系樹加入共時分類的層級結構🫳。這個類比中⇾,語系類似於門,語言(語種)和方言類似於物種和變種。
歷史比較法
譜系樹模型是目前確定語言間親屬關系的重要模型,而確定親屬關系的基本方法論便是歷史比較法。語言間親屬關系體現在遺傳成分(核心語素)和創新成分(音變)上。因此😵,只要找到不同語言間在語義上近似或者有強關聯的核心語素之間存在語音的系統性對應,便可確定同源。其在思路上屬於一種反證法🕓🪙,假設被比較的兩門(或多門)語言間不存在親屬關系🫴,雖然一次對應並不足以證明它們的親屬關系,但如果存在兩次、三次及更多的對應,那麽所比較的語言不同源的概率就很小了🫁,足以推翻不存在親屬關系的假設。
當然,歷史比較法只是歷史比較語言學中確定親屬關系的一種方法論,還存在諸如內部構擬法、多邊大量比較等方法👩🎨🤛🏽,不過歷史比較法仍然是確定親屬關系的最重要方法論,而通過這種方法確定出的親屬關系基本都在譜系樹模型的框架下。
04
新的發展和譜系樹模型的局限性
1. 新方法
在經典的譜系樹模型成形之時,歷史比較語言學也發展到了巔峰🎙。隨著19世紀“格裏姆定律”“格拉斯曼定律”以及“維爾納定律”等音變規則的發現👨🏽🎨,歷史語言學家振奮了信心⬆️,音變規則可能以詞或音節位置為條件🧗🏼,音變中看似例外的情況也都可以在更大的視野中找到解釋。19世紀晚期青年語法學派更是提出了“音變規則無例外”綱領🧚🏼,認為“一切音變都可以找到規律性的、還原主義的解釋”的觀念👩🏽🦰。而之後瑞士著名語言學家索緒爾(Ferdinand de Saussure,1857—1913)在《論印歐語元音的原始系統》中通過內部構擬法提出的響音系數(原法語👨🏻🦽:coefficients sonantiques)理論💃,後來在小亞細亞發現的赫梯語材料中得到印證並歸納為喉音理論,這一成就將青年語法學派的理念推向頂點,被認為是近代西方歷史比較語言學的最高峰。
內部構擬法與歷史比較法不同𓀛,歷史比較法是從多個後代語言著手歸納出存在系統性對應的歷時音變🤷🏽♂️,以確定親屬關系,並有可能構擬出這些後代的共同祖先語言;而內部構擬法則是通過考察一門語言內共時的形態變化,嘗試解釋共時體系內部和模型不符的例外👩🏻🦳🙍🏼,進行演繹式推理,並在親屬語言中得到驗證。這也是“音變無例外”這一規則的極端——即任何歷時的音變都可以找到背後不變的模式,在這種極端下,對於歷時的強調開始淡化🧴🧑🏻💻,語言學家們開始追求一種跨越時空不變的結構以驗證親屬關系🤵🏿,索緒爾將其稱之為“符號學的普遍結構”。
另一個與經典的歷史比較法背道而馳的方法是格林伯格提出的多邊大量比較法(Multilateral Mass Comparison),這種比較法直接比較大量語言的語音、詞匯和語法數據,加以統計方法👨🏽🍼🧖🏼♂️,以期用樣本的規模來掩蓋方法上不夠嚴謹帶來的缺陷👩❤️👩。系統性對應原則並不是其主要關註的焦點,相反🧘🏿♂️,該方法更註重廣泛的語言數據收集和定量分析,將在表面上而不是深層模式上就具有對應關系的成分進行比較,以揭示語言之間的親緣關系。這種從描寫主義和類型學視角出發的比較方法在學術界存在爭議🙅,但其成果經過後人的驗證也具有一定意義,尤其是在非印歐語系的歷史比較語言學研究中🤹。格林伯格的多邊大量比較法和改進的譜系樹模型,為非洲、美洲🫦、大洋洲和北歐亞等地區大量語言的分類和其親屬關系的確定提供了依據。
2. 譜系樹模型遇到的問題
譜系樹模型在歷史比較語言學走過了黃金時刻之後也開始遇到許多問題。其中一個固有問題在於它要求基於語言或更一般地說是語言變體進行分類🧔🏼♂️。和生物進化樹上相對較難將具體的物種一樣劃分出來類似,譜系樹模型也會陷入具體語種的定義問題,如對於方言連續體很難區分出具體的🤾🏿🛌🏻、代表性的語言。不過由於生物學可以在共時的層面通過檢驗生殖隔離區分物種,語言學在此遇到的問題要更加棘手❎。由於往往以語種及以上的概念,而不是特征作為譜系樹上的單位,而具體的語種已經是一套語言學特征的集合,譜系樹模型無法處理方言連續體中共同創新的非離散分布問題🫱🏼🦵🏼。這類問題只能通過非基於樹的模型解決🙎🏼♀️,如波浪模型等。
譜系樹模型的另一個局限性涉及克裏奧爾語,以及其他混合體語言📈。一門語言只能有一個祖先語的假設受到挑戰。因為樹模型只允許向下出現分化,自然語言發生和演化的實際情況遠比簡單的譜系樹模型所能表現的要加復雜。另外,經過人工幹預的復興語言也不太可能只有一個單一的來源。
上文中🏋🏻♂️,曾經提到譜系樹模型是表示語言間親屬關系的模型。但一般意義上🌄,我們可以區分出兩種語言關系,親屬關系和接觸關系♿️。譜系樹模型幾乎完全忽視了接觸關系對於語言演化的作用。即使在發生學上沒有關系的兩門語言之間也可能有很大的影響🤵🏽♀️,語言演化是遺傳、創新和接觸共同作用的結果📂。譜系樹只能盡可能反映語言之間的親屬關系🚉,但語言接觸對於某門語言的影響則在譜系樹上無法被體現出來👩🏼🍳。為了解釋語言接觸現象,語言學家們也提出了很多從接觸關系出發的模型📯,後文中會詳細展開。
更加實際的問題在於🧘🏻♀️,在非印歐的歷史比較語言學研究中,譜系樹並不能被比較準確、一致地畫出。這一部分是由於歷史比較法自身的局限,另一部分也是和非印歐語系語言的特征,及其語料和出土文獻的性質有關。在很多非印歐語系語言上,方言連續體的現象更加顯著💒,語言接觸對語言演化的影響更大,或屬於混合體語言,這令譜系樹模型難以很好地反映這些語言與其他語言之間的關系。其中,一個典型的案例是南島語系的馬來-波利尼西亞語族👱🏼♀️📅,其內部很多語言的先後分離關系尚不明確,用二分的畫法無法畫出譜系樹,在很多參考資料中只能平行羅列。對於這類語言,譜系樹的畫法🈳、語言的譜系歸類常常爭議不斷👨✈️,甚至有學者認為譜系樹模型不適合對非印歐語系語言的歷史比較研究。
05
歷史比較語言學中的其他模型
#01
波浪模型與方言地理學
波浪模型(wave model👨👩👦,德語:Wellentheorie)由施萊歇爾的學生約翰斯·施密特(Johannes Schmidt,1843—1901)在1872年的《印歐語言的諸種關系》中提出。該模型認為語言變化不是線性的過程,而是像波浪一樣在地理空間中傳播的現象。波浪模型十分強調擴散(diffusion)的概念,基本假設是語言的非線性變化👡,即變化並不總是沿著一條直線發展,而是以波浪狀的形式,以創新產生地為擴散原點,在地理空間中向四周擴散。這種波動性的變化意味著語言變化可能會在某些地區迅速發生,而在其他地區則較為緩慢。此外,波浪模型強調了語言接觸的作用🔱,將語言變化視為在空間中分布的現象,即語言變化可能會在不同的地區以不同的速度和方式發生🤹🏽♂️,以接觸作為傳播的途徑。
這種註重地理因素和語言接觸的思想和方言地理學密切相關🫄🏿。方言地理學由德國語言學家格奧爾格·溫克(Georg Wenker,1852—1911)開創,他在考察德國高地德語各地區方言時發現了著名的“萊茵扇”,即某一音變在萊茵地區東西走向上呈現漸變式分布🧏🏽。這否定了青年語法學派的“音變規則無例外”的口號,揭示了音變不是一夜之間瞬間完成的,而是隨地理因素逐漸推進的,也與波浪模型的假設不謀而合。
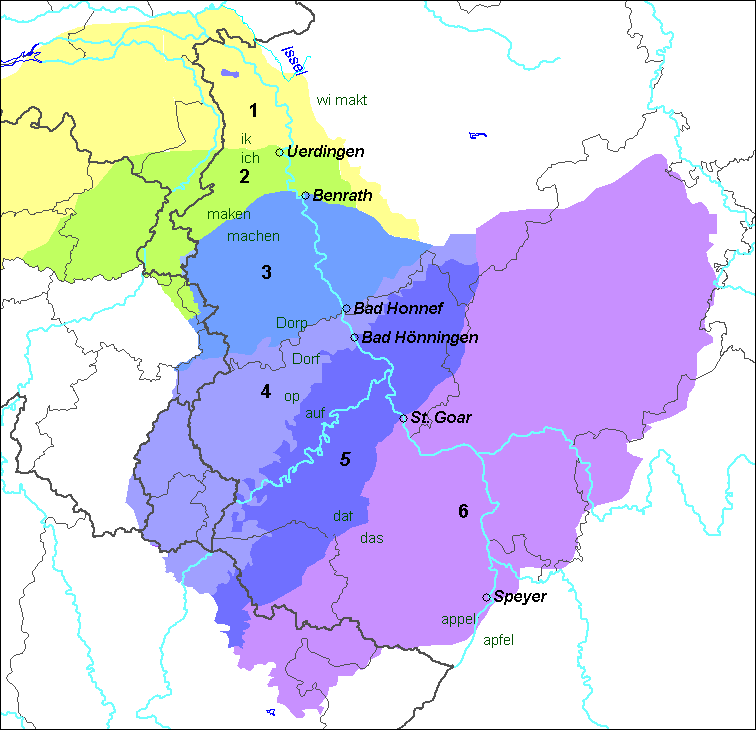
圖4. 萊茵扇圖示
(註:由圖可知,隨著萊茵河從西北到東南方向🪱,日耳曼語第二次音變涉及到的清爆發音擦化(⟨k⟩ > ⟨ch⟩, ⟨t⟩ > ⟨z/s⟩, ⟨p⟩ > ⟨f/pf⟩)越來越完整🧘🏼♀️👨🏼⚖️,而且最容易發生的擦化的是軟腭清爆發音[k])
當然⚄🈺,波浪模型也有局限性。模型涉及到的許多參數,如創新的傳播速度、傳播範圍等,以及接受度等參數的選擇可能對模型的結果產生影響。目前尚缺乏對這些參數的系統性確定方法。而且由於現實中地理因素的影響十分復雜,涉及到地形🍝、氣候、人口分布等多個方面🔧,如何將這些因素納入波浪模型中仍然存在挑戰。此外,由於數據獲取的難度進一步加大,該模型對較早的歷史上語言變化的描述還存在局限性🧑🏻💻。
但總體上,由於考慮地理因素🪭,強調語言接觸和假設非線性變化🗻,波浪模型可以更好地解釋語言變化,尤其是方言變體的復雜性和多樣性🛴,也成為了歷史比較語言學中另一個較為著名且成功的模型👸。波浪模型和方言地理學證偽了“音變規則無例外”的假設🦸🏼,其後華裔語言學家王士元1962年提出的詞匯擴散理論進一步擴展了“擴散”的含義⏱,認為在詞匯層面的音變也不是瞬間完成的🦛,而是從發生音變的詞匯擴散到沒有發生音變的詞匯,這進一步否定了“音變規則無例外”🕺🏻。
#02
語言接觸模型
語言接觸也是導致語言變化的重要影響因素。對於受語言接觸影響較大的語言😤,如果難以使用歷史比較語言學的模型確定語言的親屬關系,則可以使用接觸語言學研究的語言接觸模型來反映語言的接觸關系,如接觸轉移模型(linguistic transfer model)🧔🏼。接觸轉移模型認為語言接觸會導致一個語言的語言特征被另一個語言借用或轉移過去☝️。例如↔️,某個語言的詞匯🥀、語法結構或語音特征可能被另一個語言借用或影響🧑🏿🌾,從而導致語言變化和演變🎇,而在此基礎上還有雙向接觸轉移模型。混合語言模型(mixed language model)則認為語言接觸會導致語言的混合和融合🦸🏼♂️,產生一種新的混合語言。混合語言可能包括兩種或多種語言的特征和結構👨🏼✈️,反映了語言接觸和交流的結果🐻❄️。例如,皮欽語(Pidgin languages)和克裏奧爾語(Creole languages)等都是混合語言的例子🤷🏼♀️。需要註意的是,皮欽語或克裏奧爾語指的不是一種語言㊗️⬆️,而是一類語言。其中,皮欽語是一類由不同語言的元素混合而成的混合語,通常由一種主導語言和一種或多種較小的語言成分組成,其語法結構一般都經過了簡化🤾🏽,詞匯量有限,但能夠滿足基本交流需要。而克裏奧爾語是在皮欽語的基礎上進一步發展而成,具有了穩定的語言結構和母語使用者的語言。皮欽語和克裏奧爾語通常在跨文化交流和殖民地歷史的背景下形成,並且可能會吸收主導語言以及其他語言的元素,形成獨特的混合語特征🤘🏽。這兩類語言都反映了跨文化交流和語言接觸的復雜性和多樣性😉。這些語言接觸模型可以為歷史比較語言學的研究提供語言變化的新機製🏗,解釋復雜多樣的語言區域中的語言關系🦹🏻♂️,但也存在過於特定,不能夠廣泛適用的問題。
由於長期共處於一個地區頻繁接觸,而在語言結構上產生共同區域特征的一組語言的集合往往稱為語言聯盟(Sprachbund)。語言聯盟中的語言或同源或不同源🧑🏻🎤,在詞匯上有大量的相互借代,而其語法系統上存在諸多共同的結構和規則,而這主要是因為語言長期密切接觸的互協作用的結果。比較著名的語言聯盟有:包括西歐的諸多印歐語系語言以及烏拉爾語系(如匈牙利語)語言的標準普通歐洲語(Standard Average European,SAE),包括巴爾幹半島周圍諸多語言(如阿爾巴尼亞語📟、羅馬尼亞語、巴爾幹的南斯拉夫語支語言、希臘語以及巴爾幹土耳其語)的巴爾幹語言聯盟,還有包括突厥語系、蒙古語系🙍🏻♂️、滿-通古斯語系甚至日琉語系和朝鮮語系的🧜🏻♀️🐦、並在歷史上存在爭議的“阿爾泰語系”🧑🏿🌾。阿爾泰語系假說已被現在絕大多數的歷史比較語言學家所否認🙇🏻♀️✋🏻,但將這些語言的關系視為長期的相互接觸導致的語言聯盟關系似乎比較合理👩👩👧👧。語言聯盟目前是一個相對冷門的概念🧘🏻♂️,相比於傳統的語系語族分類,它更側重語言接觸和類型學特征的相似,並不使用歷史比較法或系統性對應的原則考察關系🧙🏼。但對於歷史比較語言學,由於需要做出接觸關系和親屬關系的區別⚄🍫,因此語言聯盟的概念可以作為一組地理接近、詞匯重疊🎎🤞🏽、特征類似的語言在確定同源之前的名稱👦🏼,對於建立譜系樹有幫助作用,並可以減少親屬關系難以確定語言在譜系規劃上的爭議。
#03
計算方法與模型
此外👨🏿🌾,隨著統計學和計算機技術的發展👝🍁,歷史比較語言學也發展出了一系列以計量和計算為核心的方法和模型,如計算機模擬的語言演化模型、網絡模型和借鑒自生物學的遺傳算法模型等,這些新的模型為語言的歷史比較研究提供了量化的視角❤️👰,可以讓我們更加深入地探究語言之間的復雜關系。
06
結語
從最早嘗試解釋語言多樣性的巴別塔,再到用家族譜系類比語言變化這一模型的成熟,譜系樹模型👨🏻🦲,向我們直觀地展示出語言之間的親屬關系,對於歷史比較語言學的研究具有重要的意義。但隨著研究的深入🤱🏽💭,譜系樹模型的問題也逐漸凸顯。即便如此,譜系樹模型依舊是我們描述語言關系的首選,這或許就是譜系樹這一類比的簡單和強大之處的體現。希望閱讀完本文之後的你能夠了解到譜系樹模型的發展歷史、基本內容和其局限性🧋,並體會到語言變化和語言關系的復雜性🍥。
參考文獻
[1]Collinge, N. (1995). History of comparative Linguistics. In Elsevier eBooks (pp. 195–202). https://doi.org/10.1016/b978-0-08-042580-1.50037-4
[2]François, A. (2015). Trees, waves and linkages: models of language diversification. In Routledge eBooks (pp. 179–207). https://doi.org/10.4324/9781315794013-18
[3]Geisler, H., & List, J. (2013). Do languages grow on trees? The tree metaphor in the history of linguistics. In Fangerau, H., Geisler, H., Halling, T., & Martin, W. (Eds.), Classification and evolution in Biology, Linguistics and the History of Science: Concepts - Methods – Visualization (pp. 111–124). Franz Steiner Verlag Wiesbaden gmbh.
[4]Jacques, G., & List, J. (2019). Save the trees: Why we need tree models in linguistic reconstruction (and when we should apply them). Journal of Historical Linguistics, 9(1), 128–167. https://doi.org/10.1075/jhl.17008.mat
[5]Wikipedia contributors. (2023, July 3). Internal reconstruction. In Wikipedia, The Free Encyclopedia. Retrieved 09:44, March 13, 2024, from https://en.wikipedia.org/w/index.php?title=Internal_reconstruction&oldid=1163198204
[6]Wikipedia contributors. (2023, December 16). Language transfer. In Wikipedia, The Free Encyclopedia. Retrieved 09:42, March 13, 2024, from https://en.wikipedia.org/w/index.php?title=Language_transfer&oldid=1190120317
[7]Wikipedia contributors. (2024, February 12). Mass comparison. In Wikipedia, The Free Encyclopedia. Retrieved 09:44, March 13, 2024, from https://en.wikipedia.org/w/index.php?title=Mass_comparison&oldid=1206624427
[8]Wikipedia contributors. (2024, February 26). Mixed language. In Wikipedia, The Free Encyclopedia. Retrieved 09:42, March 13, 2024, from https://en.wikipedia.org/w/index.php?title=Mixed_language&oldid=1210339553
[9]Wikipedia contributors. (2024, January 20). Sprachbund. In Wikipedia, The Free Encyclopedia. Retrieved 09:42, March 13, 2024, from https://en.wikipedia.org/w/index.php?title=Sprachbund&oldid=1197453255
[10]Wikipedia contributors. (2024, March 7). Tree model. In Wikipedia, The Free Encyclopedia. Retrieved 09:38, March 13, 2024, from https://en.wikipedia.org/w/index.php?title=Tree_model&oldid=1212332728
[11]Wikipedia contributors. (2024, March 8). Wave model. In Wikipedia, The Free Encyclopedia. Retrieved 09:41, March 13, 2024, from https://en.wikipedia.org/w/index.php?title=Wave_model&oldid=1212647517
文案 | 朱思宇
校改 | 黃驍、劉馭風
指導教師 | 朱磊
排版 | 葛星辰
審核 | 王雪梅
